Estimación del Tiempo de Permanencia Portuaria mediante el Aprendizaje Automático: Un Análisis Basado en Datos AIS para la Competitividad de los Puertos de Panamá
Aguilar, Ezequiel
Georgia Tech Panama Logistics Innovation & Research Center
Ciudad de Panamá, Panamá
https://orcid.org/0000-0003-1001-8805
Lasso, Álvaro
Georgia Tech Panama Logistics Innovation & Research Center
Ciudad de Panamá, Panamá
https://doi.org/10.33412/apanac.2025.50
Abstract
Port dwell time is a critical bottleneck in container shipping and a key factor in national logistic performance. Current operational methods, which often rely on static schedules, result in poor resource allocation and inaccurate time estimates. This study develops and validates a predictive model for port dwell time using high-frequency AIS data from Panama’s five main ports. We use the SHAP method to identify and select the most influential features, capturing the actual operational dynamics of vessels. A comparative benchmark analysis demonstrates that tree-based ensemble models consistently outperform traditional linear approaches. The LightGBM (LGBR) model achieved the highest predictive accuracy across most ports (e.g., PAMIT, R2: 0.465), with optimized XGBoost also showing significant performance gains. The resulting model provides a practical tool for optimizing dock utilization and a quantitative framework for performance benchmarking. This contributes to reducing logistics costs and improving the operational efficiency of Panama’s maritime trade.
Keywords: Port Performance, Dwell Time, Containers Ships
Resumen
La eficiencia del transporte marítimo de contenedores es un pilar fundamental del comercio global, donde el tiempo de permanencia portuaria (dwell time) emerge como un indicador crítico de la competitividad nacional. Las metodologías operativas actuales, que a menudo se basan en horarios estáticos, generan ineficiencias y estimaciones imprecisas. Este estudio aborda dicha deficiencia mediante el desarrollo y validación de un modelo predictivo avanzado, enfocado en los cinco principales puertos de Panamá, un nodo logístico estratégico. La metodología emplea datos históricos de alta frecuencia del Sistema de Identificación Automática (AIS) para capturar la dinámica operativa real de los buques, optimizando la selección de características influyentes a través del método SHAP. La evaluación comparativa demostró que los modelos de ensamble basados en árboles superan consistentemente a los enfoques lineales. Entre ellos, el modelo LightGBM (LGBR) mostró el mejor rendimiento predictivo en la mayoría de los puertos panameños (ej., PAMIT, R2: 0.465), mientras que el XGBoost optimizado también evidenció mejoras sustanciales. Este trabajo establece una herramienta robusta para la optimización proactiva de la utilización de muelles y un marco cuantitativo para el benchmarking continuo, contribuyendo directamente a la reducción de costos logísticos y al refuerzo de la posición competitiva de Panamá en el comercio internacional.
Palabras claves: Port Performance, Dwell Time, Containers Ships
1. Introducción
El transporte marítimo es reconocido como un pilar insustituible del comercio global, responsable de movilizar más del 80% del volumen total de la carga. En este contexto, los puertos funcionan como nodos críticos que determinan la fluidez y eficiencia de las cadenas de suministro internacionales. La eficiencia portuaria se ha convertido en un determinante clave de la competitividad nacional. Sin embargo, el crecimiento exponencial del comercio ha intensificado la congestión, generando tiempos de espera prolongados (dwell times), lo que se traduce en un aumento de los costos operativos y una reducción de la fiabilidad logística. Convencionalmente, la estimación del tiempo de permanencia de los buques se ha apoyado en horarios estáticos, un enfoque que no logra capturar la complejidad no lineal y la dinámica operativa real de los puertos, resultando en predicciones imprecisas y asignación subóptima de recursos. Dada la posición estratégica de Panamá como nodo logístico crucial para el comercio mundial, es imperativo desarrollar un enfoque predictivo más robusto y dinámico que aborde estas ineficiencias.
Los enfoques existentes para predecir los tiempos de permanencia en puertos presentan limitaciones clave. Estos métodos se pueden clasificar en varias categorías con debilidades específicas:
- Modelos Estadísticos: Enfoques como la Regresión o ARIMA son simples, pero no consiguen capturar los patrones complejos y no lineales de las operaciones portuarias del mundo real, lo que impacta negativamente su precisión [1] [2].
- Modelos basados en Simulación: Estos métodos, si bien ofrecen mejoras, requieren un alto costo computacional. Además, su aplicabilidad práctica se ve limitada, ya que no se generalizan bien a diferentes puertos o distintas condiciones operativas [3] [4].
- Modelos de Aprendizaje Automático (Machine Learning - ML): Aunque son más precisos que los métodos estadísticos, modelos como Random Forest (RF), Support Vector Machines (SVM) y Artificial Neural Networks (ANN) presentan una generalización limitada. Esto se debe a que tienden a depender de las condiciones específicas y de los datos de un solo puerto [5] [6].
- Modelos de Aprendizaje Profundo (Deep Learning - DL): Técnicas avanzadas como Long Short-Term Memory (LSTM) y Recurrent Neural Networks (RNN) exigen grandes volúmenes de datos y una significativa capacidad de poder computacional. Este requerimiento dificulta su implementación efectiva en muchos entornos portuarios [7] [8].
El objetivo principal de esta investigación es construir y validar un modelo de aprendizaje automático de alta precisión para la estimación del tiempo de permanencia de buques portacontenedores en los cinco (5) principales puertos de Panamá, buscando optimizar la utilización de muelles y establecer una metodología de benchmarking empírica para el desempeño portuario.
2. método
Fuente y Procesamiento de Datos. La base de datos utilizada para el modelado comprende registros históricos de alta frecuencia del Sistema de Identificación Automática (AIS), complementados con características estáticas de los buques, como la eslora, manga y capacidad TEU. El estudio se focalizó en los cinco principales puertos de Panamá (PAMIT, PABLB, PAONX, PAROD, PACTB). Para garantizar la exactitud de la variable dependiente (tiempo de permanencia), se definieron geocercas (Ilustración 1) para las áreas de muelle, permitiendo calcular el Tiempo Real de Atraque (ATB) y el Tiempo Real de Salida (ATD). El preprocesamiento incluyó la detección y depuración de valores atípicos (outliers) mediante el método del rango intercuartílico (IQR), proceso esencial para aumentar la calidad del conjunto de datos y la robustez del modelo resultante.

Ilustración 1. Representación del Puerto de Balboa (PABLB), mostrando la geocerca definida y las trayectorias de buques compuestas por puntos AIS.
Ingeniería y Selección de Características. Se llevó a cabo una exhaustiva ingeniería de características, explorando variables como el historial de tiempo de permanencia de buques similares, la ruta del buque (dirección northbound o southbound), la información sobre el cruce del Canal de Panamá y las características físicas (Capacidad TEU, arqueo bruto, peso muerto). Para identificar y seleccionar las variables con mayor poder predictivo, se empleó el método de Explicación Aditiva de Shapley (SHAP). El análisis SHAP (lustración 2), anclado en la teoría de juegos, permite cuantificar la contribución de cada característica a la predicción final, proveyendo una base teórica sólida para una evaluación justa y consistente. Este procedimiento fue crucial, ya que se confirmó que la selección de características basada en SHAP no resultaba en una pérdida de rendimiento estadísticamente significativa en comparación con el uso de todas las características, superando a técnicas como el Análisis de Componentes Principales (PCA), que causó una degradación significativa en la precisión predictiva.
Modelización y Evaluación. Para la estimación del tiempo de permanencia, se evaluó sistemáticamente una diversidad de modelos de regresión, incluyendo enfoques lineales (Regresión Lineal, Ridge) y, primariamente, modelos de conjunto (ensemble) de alto rendimiento: LightGBM (LGBR) y XGBoost (XGBR). Estos algoritmos fueron seleccionados por su probada eficacia en la identificación y explotación de interacciones no lineales complejas en grandes volúmenes de datos estructurados, como los encontrados en las operaciones portuarias. La evaluación de rendimiento se cuantificó utilizando el Error Cuadrático Medio (RMSE), el Error Absoluto Medio (MAE) y el Coeficiente de Determinación (). Se aplicó también la optimización de hiperparámetros en el modelo XGBR mediante un Algoritmo Genético (GA) y se implementó un modelo de Stacking Ensemble para maximizar la precisión. La significancia estadística de las diferencias de rendimiento entre los modelos fue verificada mediante pruebas ANOVA y t-test pareadas.
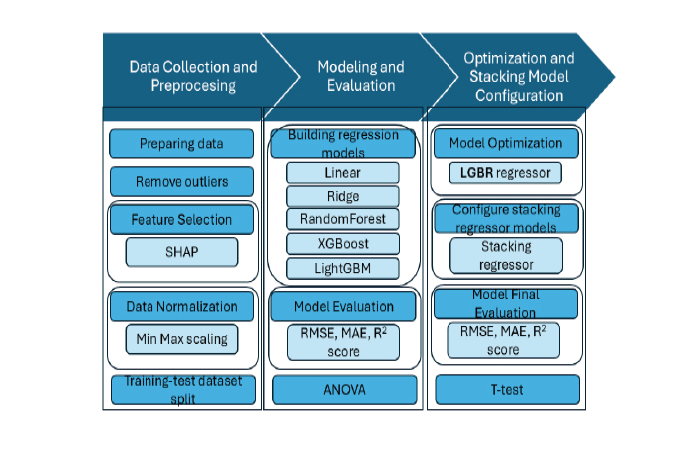
Ilustración 2. Modelo SHAP (Shapley Additive Explanations)
3. Resultados
Los resultados de la evaluación inicial mostraron que los modelos de regresión basados en árboles de ensamble (RFR, XGBR, LGBR, GBR) ofrecieron un rendimiento predictivo superior a los modelos lineales (LR, Ridge), lo cual es consistente con la naturaleza compleja y no lineal de la dinámica portuaria. En el contexto de un estudio general (no específico por puerto), el XGBoost Regressor (XGBR) se identificó como el modelo individual con el mejor desempeño inicial. La aplicación de optimización de hiperparámetros a través del Algoritmo Genético (GA) mejoró la precisión del XGBR en el conjunto de prueba, como se observó consistentemente en la mayoría de los puertos panameños analizados (PAMIT, PABLB, PAONX, PAROD, PACTB).
En el análisis detallado por puerto, se confirmó que la dinámica operativa de cada terminal es lo suficientemente única como para requerir modelos especializados. En este análisis pormenorizado, el modelo LightGBM (LGBR) demostró el mejor rendimiento individual en términos de R2 para varios puertos clave, como PAMIT (R2: 0.465, RMSE: 7.477), PAROD (R2: 0.257) y PABLB (R2: 0.178). En el análisis de conjunto más amplio, si bien el modelo de Stacking Ensemble logró un MAE marginalmente superior en la fase de prueba en comparación con el XGBR optimizado, las diferencias de rendimiento entre el Stacking y el XGBR optimizado generalmente no resultaron ser estadísticamente significativas en el análisis por puerto.
Discusión La superioridad de los modelos de impulso de gradiente (XGBoost y LightGBM) reafirma su adecuación para capturar las interacciones complejas entre las características que influyen en el tiempo de permanencia, algo que los modelos estadísticos tradicionales no pueden lograr eficientemente. El uso exitoso del análisis SHAP fue crucial, no solo para la selección de las variables más predictivas (como las características físicas del buque y la información de la naviera o muelle específico), sino también para dotar al modelo de la interpretabilidad necesaria. Esta interpretabilidad es fundamental para que los operadores portuarios puedan confiar y utilizar las predicciones en la asignación proactiva de muelles, superando así la limitación de generalización reportada en estudios anteriores que se basan en datos de un solo puerto.
4. CONCLUSIONES
Este estudio ha demostrado la utilidad y el potencial de los modelos predictivos basados en aprendizaje automático para la estimación precisa del tiempo de permanencia portuaria, validando el uso de datos AIS de alta frecuencia y algoritmos de ensamble como XGBoost y LightGBM por su robustez ante la complejidad operativa. La principal contribución reside en la provisión de una herramienta predictiva de alta precisión para los puertos panameños y en el establecimiento de un marco cuantitativo riguroso para la evaluación y el benchmarking continuo del desempeño portuario.
Las implicaciones prácticas de estos hallazgos son significativas. Unas predicciones más precisas permiten la optimización proactiva de la programación de atraques y la asignación eficiente de recursos, lo que se traduce directamente en una reducción de la congestión y los costos operativos para las navieras. Además, la minimización de los tiempos de espera tiene un impacto ambiental positivo al reducir el consumo de combustible y, consecuentemente, las emisiones de gases de efecto invernadero. Esto no solo mejora la fiabilidad de la cadena de suministro, sino que también refuerza la competitividad de Panamá como nodo logístico global.
Como futuras líneas de investigación, se propone la incorporación de variables externas en tiempo real (tales como condiciones meteorológicas o niveles dinámicos de congestión) para mejorar la adaptabilidad y precisión del modelo. También es recomendable explorar arquitecturas de modelos más diversas, como las Redes Neuronales Recurrentes (ej., LSTM) o modelos híbridos, para una captura más sofisticada de las dependencias temporales. Finalmente, la expansión geográfica y la validación del modelo utilizando datos de otros puertos a nivel global permitirían extender su aplicabilidad y robustez.
Referencias
- G. Fancello, C. Pani, M. Pisano, P. Serra, P. Zuddas, P. Fadda, Prediction of arrival times and human resources allocation for container terminal, Maritime Economics & Logistics 2011 13:2 13 (2011) 142–173. doi:10.1057/MEL.2011.3
- J. Farhan, G. P. Ong, Forecasting seasonal container throughput at international ports using sarima models, Maritime Economics & Logistics 2016 20:1 20 (2018) 131–148. doi:10.1057/MEL.2016.13.
- X. Xiaoyingjie, Z. Zhanghao, L. Lisong, Dynamic data driven multi-agent simulation in maritime traffic, Proceedings 2009 International Conference on Computer and Automation Engineering, ICCAE 2009 (2009) 234–237 doi:10.1109/ICCAE.2009.17.
- J. Ksciuk, S. Kuhlemann, K. Tierney, A. Koberstein, Uncertainty in maritime ship routing and scheduling: A literature review, European Journal of Operational Research 308 (2023) 499–524. doi:10.1016/J.EJOR.2022.08.006.
- L. R. Abreu, I. S. Maciel, J. S. Alves, L. C. Braga, H. L. Pontes, A decision tree model for the prediction of the stay time of ships in brazilian ports, Engineering Applications of Artificial Intelligence 117 (2023) 105634. doi:10.1016/J.ENGAPPAI.2022.105634.
- W. Zhang, Y. Zou, J. Tang, J. Ash, Y. Wang, Short-term prediction of vehicle waiting queue at ferry terminal based on machine learning method, Journal of Marine Science and Technology 2016 21:4 21 (2016) 729–741. doi:10.1007/S00773-016-0385-Y.
- G. Tang, J. Lei, C. Shao, X. Hu, W. Cao, S. Men, Short-term prediction in vessel heave motion based on improved lstm model, IEEE Access 9 (2021) 58067–58078. doi:10.1109/ACCESS.2021.3072420.
- L. Kolley, N. Rückert, M. Kastner, C. Jahn, K. Fischer, Robust berth scheduling using machine learning for vessel arrival time prediction, Flexible Services and Manufacturing Journal 2022 35:1 35 (2022) 29–69. doi:10.1007/S10696-022-09462-X.
Autorización y Licencia CC
Los autores autorizan a APANAC XX a publicar el artículo en las actas de la conferencia en Acceso Abierto (Open Access) en diversos formatos digitales (PDF, HTML, EPUB) e integrarlos en diversas plataformas online como repositorios y bases de datos bajo la licencia CC:
Attribution-NonCommercial-ShareAlike 4.0 International (CC BY-NC-SA 4.0) https://creativecommons.org/licenses/by-nc-sa/4.0/.
Ni APANAC XX ni los editores son responsables ni del contenido ni de las implicaciones de lo expresado en el artículo.